AI GPU Programming - Cuda Basics
Basic building blocks for GPU programming
Cuda Programming Basics
CUDA (Compute Unified Device Architecture) is NVIDIA’s parallel computing platform and programming model. It allows you to write C/C++-like code that runs on the GPU, which is highly parallel and suitable for tasks like matrix operations, image processing, and machine learning. Here’s a quick explanation of how CUDA programming works, especially the concepts of blockDim, threadIdx, and blockIdx.
🧠 The Execution Model
When you launch a CUDA kernel (a function that runs on the GPU), you define: Grid: A collection of blocks Block: A collection of threads. Each thread executes the same kernel code, but works on different data depending on its thread ID.
💡 Key Built-In Variables
These three built-in variables help identify which thread is executing:
threadIdx- Identifies the thread within a block
- It’s a 3D index: threadIdx.x, threadIdx.y, threadIdx.z
blockIdx- Identifies the block within the grid
- Also 3D: blockIdx.x, blockIdx.y, blockIdx.z.
blockDim- Tells how many threads are in a block (in each dimension)
- 3D: blockDim.x, blockDim.y, blockDim.z
🧮 Calculating Global Thread Index
Often, you want a 1D global thread index to map each thread to an element in an array. You compute it like this: int idx = blockIdx.x * blockDim.x + threadIdx.x;
This gives each thread a unique index across the entire grid.
✅ Example: Add Two Arrays
Here’s a minimal CUDA example to add two arrays:
1
2
3
4
5
6
__global__ void vectorAdd(float *A, float *B, float *C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
Launching the Kernel
1
2
3
4
5
int N = 1000;
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(A_d, B_d, C_d, N);
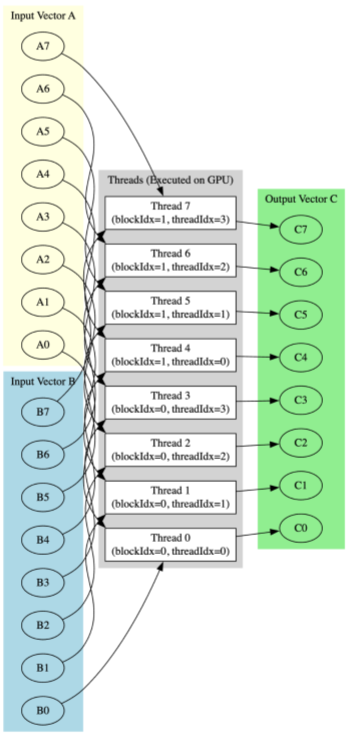
🪟 Visualization - vector_add
Let’s say we vector_add A and B with both having 8 elements each. We use block size of 4 and 2 thread blocks.
It means:
1
2
3
4
blockDim.x = 4
blockIdx.x = 0, 1
threadIdx.x = 0, 1, 2, 3
blockIdx.x * blockDim.x + threadIdx.x: 0, 1, 2, 3, 4, 5, 6, 7
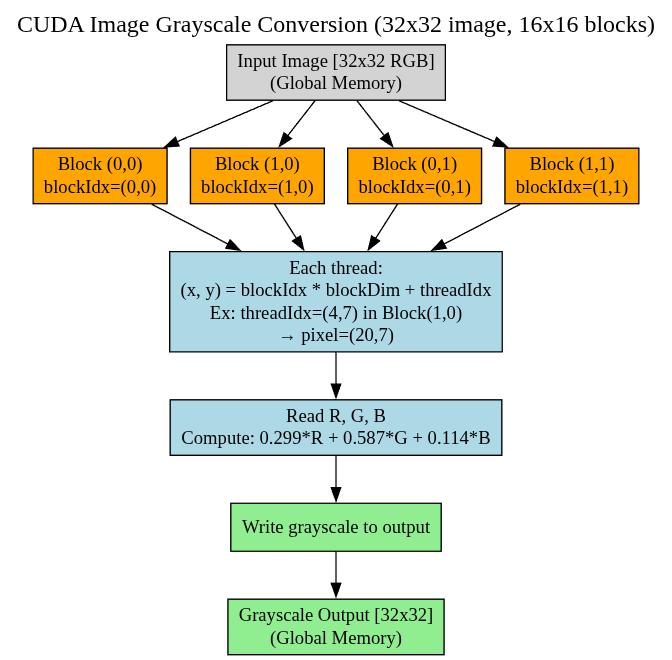
🪟 Visualization - image_grayscale
Let’s take below example
- Image size: 32 x 32 pixels
- Block size: 16 x 16 threads
- Grid size: 2 x 2 blocks (since 32 / 16 = 2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int width = 32, height = 32;
float *d_input, *d_output;
size_t size = width * height * sizeof(float);
cudaMalloc(&d_input, size);
cudaMalloc(&d_output, size);
// Assume input is copied from host
dim3 blockDim(16, 16);
dim3 gridDim((width + 15) / 16, (height + 15) / 16);
image_grayscale<<<gridDim, blockDim>>>(d_input, d_output, width, height);
cudaDeviceSynchronize();
Mapping out how blocks will run computations:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
blockIdx.x = 0, 1
blockIdx.y = 0, 1
threadIdx.x = 0 to 15
threadIdx.y = 0 to 15
For block (0,0):
thread (0,0) => pixel (0,0)
thread (15,15) => pixel (15,15)
For block (1,0):
thread (0,0) => pixel (16,0)
thread (15,15) => pixel (31,15)
For block (1,1):
thread (0,0) => pixel (16,16)
thread (15,15) => pixel (31,31)
..
🔁 Summary
threadIdx: Thread ID within a blockblockIdx: Block ID within the gridblockDim: Number of threads per blockgridDim: (Optional) Number of blocks in the grid
🎮 Interactive CUDA Execution Visualizer
Below is an interactive visualization showing how CUDA grids, blocks, warps, and threads execute in parallel on a GPU. This demonstrates a simple vector addition kernel with 4 blocks (2×2 grid) and 128 threads per block (16×8).