Triton Kernels - Fused Softmax - 2
Worklog: Performance debugging Triton Kernel
As a recap, in the prevous post I implemented a Triton softmax kernel. The kernel achieves competitive performance with PyTorch at small-to-medium vocabulary sizes but shows degradation at very large vocabularies (32K+) and large batch_sizes. In this post, we will use some profiling tools to debug why that might be the case.
NCU Profiler
I provided a snapshot of ncu-ui in the previous post, but let’s look deeper into the results. You can run a full ncu profiler from the cli like below and then inspect the results in the ui.
1
2
3
4
# Pytorch version
ncu --set full -o output python softmax_benchmark.py --M 8192 --N 32000 --iters 1000 --backend torch
# Triton version
ncu --set full -o output python softmax_benchmark.py --M 8192 --N 32000 --iters 1000 --backend triton
The profiling results provide you a lot of details, but on careful inspection – couple of things jumped out.
Scheduler and Warp State Statistics
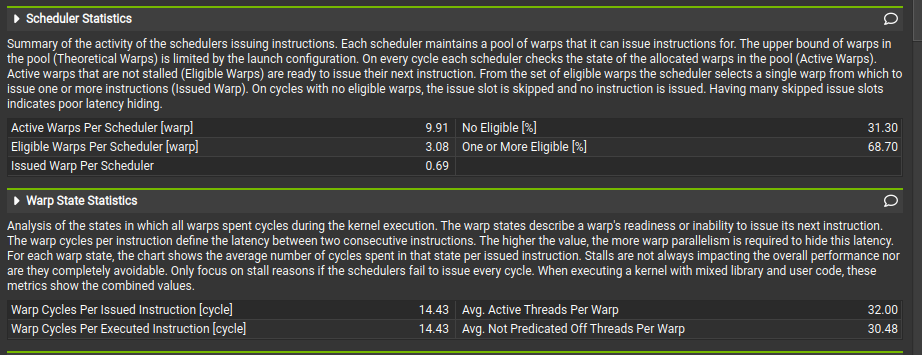
Triton
Torch
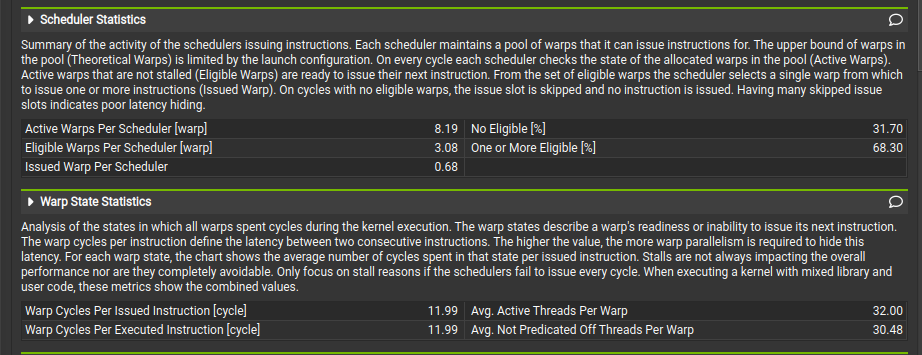
- The metric Warp Cycles per Issued Instruction 📊 reflects the average latency between consecutive instructions. The slower kernel shows a higher value (14.43 vs. 11.99) ⚠️, meaning warps spend more cycles stalled before issuing the next instruction.
- This indicates reduced instruction throughput 📉 and a greater need for warp parallelism to hide latency. The stall breakdown should be examined 🔍 to identify whether memory, dependencies, or occupancy limits are the main cause.
Warp stalls
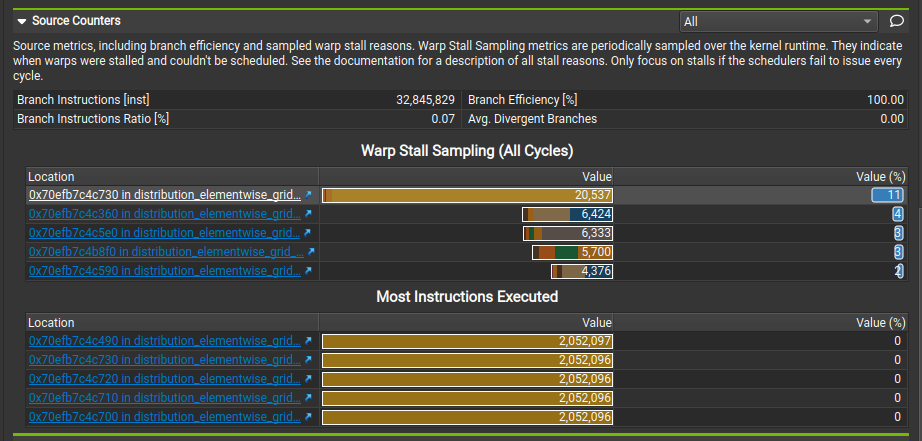
Triton
Torch
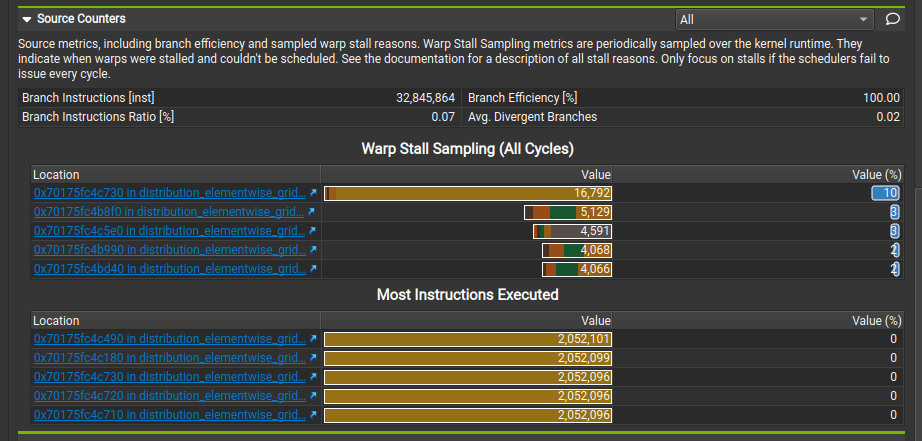
We can see from the above distribution that warps are stalled a lot more for the top 4-5 locations for Triton vs Torch. NCU allows you click into where the stalls are coming from. Let’s see that next:
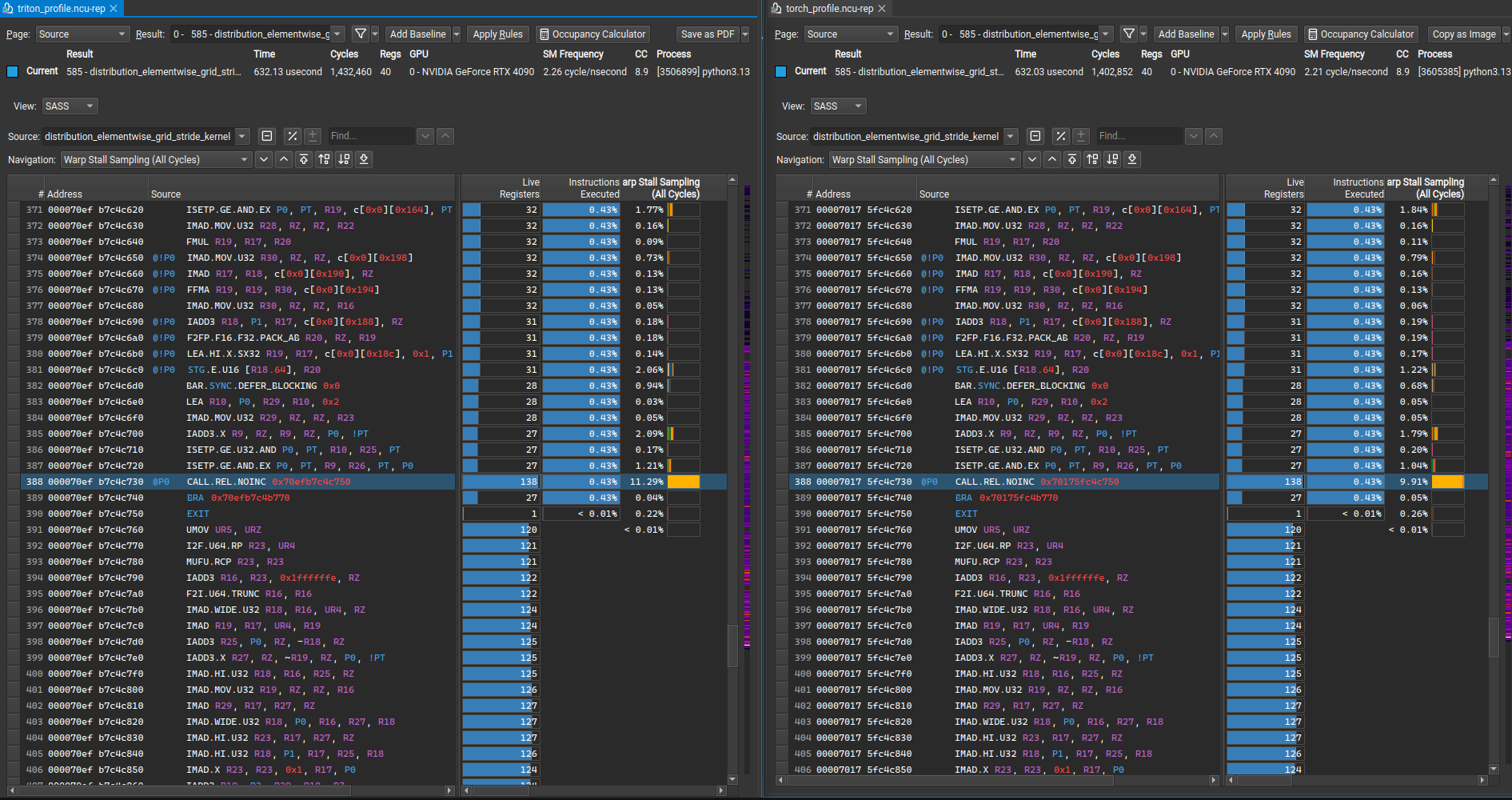
The Specific Instruction: @P0 CALL.REL.NOINC 0x70efb7c4c750
1
@P0 CALL.REL.NOINC 0x70efb7c4c750 138 2052096 20537
This instruction is:
@P0: Predicated execution - only executes if predicate register P0 is trueCALL.REL.NOINC: A relative function call with no automatic increment0x70efb7c4c750: The target address to call138: Cycle number when this instruction executes2052096: Number of threads executing this instruction20537: Stall cycles - this is why it’s concerning!
Looking at the instructions where 0x70efb7c4c750 is used:
466 @!P0 MOV R35, R18 132 1 0
467 @!P0 BRA 0x70efb7c4cd30 132 1
468 FSETP.GEU.FTZ.AND P0, PT, R18, RZ, PT 132 0
469 @!P0 IMAD.MOV.U32 R35, RZ, RZ, 0x7fffffff 132 0
470 @!P0 BRA 0x70efb7c4cd30 132 0
471 FSETP.GTU.FTZ.AND P0, PT, |R18|, +INF , PT 132 0
472 @P0 FADD.FTZ R35, R18, 1 132 0
473 @P0 BRA 0x70efb7c4cd30 132 0 0
This appears to be implementing a floating-point validation and sanitization routine - likely part of some validation for NaN, inf.
1
2
466 @!P0 MOV R35, R18 # If P0 is false, copy R18 to R35
467 @!P0 BRA 0x70efb7c4cd30 # If P0 is false, branch to exit
This handles some initial condition where if P0 is false, it just passes through the input value in R18.
1
2
3
468 FSETP.GEU.FTZ.AND P0, PT, R18, RZ, PT # Set P0 = (R18 >= 0.0)
469 @!P0 IMAD.MOV.U32 R35, RZ, RZ, 0x7fffffff # If negative, set R35 = NaN
470 @!P0 BRA 0x70efb7c4cd30 # If negative, branch to exit
Purpose: Handle negative numbers (probably related to sqrt)
- Tests if R18 (input) is greater than or equal to zero
- If the number is negative (!P0), it sets R35 to
0x7fffffff(which is NaN in IEEE 754) and exits - This suggests the function only accepts non-negative inputs
1
2
3
471 FSETP.GTU.FTZ.AND P0, PT, |R18|, +INF, PT # Set P0 = (|R18| > +INF)
472 @P0 FADD.FTZ R35, R18, 1 # If NaN, add 1 (propagates NaN)
473 @P0 BRA 0x70efb7c4cd30 # If NaN, branch to exit
Purpose: Handle NaN inputs
- Tests if the absolute value of R18 is greater than infinity (only true for NaN)
- If input is NaN, it adds 1 to propagate the NaN and exits
- The
FADD.FTZ R35, R18, 1ensures NaN propagation (NaN + anything = NaN)
This suggests the kernel is spending significant time validating inputs resulting in warp divergence.
I tried changing the max value to something like -100.0 but that did not seem to help.
Comparing this to torch version:
1
388 @P0 CALL.REL.NOINC 0x70175fc4c750 138 2052096 16792
0x70175fc4c750is not used anywhere else which seems to indicate there is no such branching in the torch version.
I have uploaded the assembly to gists for detailed comparison:
SASS Comparison
🔍 SASS Reference
The following gist contains the SASS assembly output for both Triton and PyTorch kernels for reference.
triton_sass.txt- SASS output from the Triton softmax kerneltorch_sass.txt- SASS output from PyTorch implementation
Proton profiler
I also briefly tested the proton profiler to explore the profiling capabilities of the tool. Nice talk on it from triton conference from last year:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
#!/usr/bin/env python3
import sys
import torch
import click
from loguru import logger
import triton.profiler as proton
# Import the existing softmax kernel
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from softmax import softmax, pytorch_softmax
# Ensure CUDA is available
if not torch.cuda.is_available():
logger.error("CUDA is not available. This script requires a CUDA-capable GPU.")
sys.exit(1)
DEVICE = torch.device("cuda")
def profile_softmax_with_proton(
M, N, dtype=torch.float16, backend="triton", profile_name="softmax_profile"
):
"""
Profile softmax kernel using Triton's Proton profiler.
Args:
M: Number of rows (batch dimension)
N: Number of columns (feature dimension)
dtype: Data type for tensors
backend: Either "triton" or "torch"
profile_name: Name for the profile output
"""
logger.info(f"Profiling {backend} softmax with M={M}, N={N}, dtype={dtype}")
logger.info(f"Profile will be saved as: {profile_name}")
# Select softmax function
if backend == "triton":
softmax_fn = softmax
elif backend == "torch":
softmax_fn = pytorch_softmax
else:
raise ValueError(f"Unknown backend: {backend}")
# Create input tensor
x = torch.randn(M, N, dtype=dtype, device=DEVICE) * 2.0
# Warmup run
logger.info("Running warmup...")
for _ in range(5):
_ = softmax_fn(x)
# Profile the kernel execution
logger.info("Starting Proton profiling...")
_ = proton.start(f"{profile_name}", backend="cupti")
for _ in range(1000):
output = softmax_fn(x)
proton.finalize()
# Move the generated file to the desired name with backend suffix
import shutil
import os
final_filename = f"{profile_name}_{backend}.hatchet"
if os.path.exists("proton.hatchet"):
shutil.move("proton.hatchet", final_filename)
logger.success(f"Profiling completed! Profile saved to: {final_filename}")
else:
logger.warning("proton.hatchet not found, profile may not have been generated")
logger.info(f"To view the profile, use: proton-viewer {final_filename}")
return output
@click.command()
@click.option("--M", type=int, required=True, help="Number of rows (batch dimension)")
@click.option(
"--N", type=int, required=True, help="Number of columns (feature dimension)"
)
@click.option(
"--backend",
type=click.Choice(["triton", "torch"]),
default="triton",
help="Backend to use: triton (custom kernel) or torch (PyTorch)",
)
@click.option(
"--dtype",
type=click.Choice(["float16", "float32"]),
default="float16",
help="Data type for tensors",
)
@click.option(
"--profile-name",
type=str,
default="softmax_profile",
help="Name for the profile output file",
)
def main(m, n, backend, dtype, profile_name):
"""Profile softmax kernel using Triton's Proton profiler."""
# Convert dtype string to torch dtype
dtype_map = {"float16": torch.float16, "float32": torch.float32}
dtype_tensor = dtype_map[dtype]
logger.info(f"Starting {backend} softmax profiling with parameters:")
logger.info(f" Backend: {backend}")
logger.info(f" M (rows): {m}")
logger.info(f" N (cols): {n}")
logger.info(f" dtype: {dtype}")
logger.info(f" Profile name: {profile_name}")
# Run profiling
output = profile_softmax_with_proton(m, n, dtype_tensor, backend, profile_name)
logger.success("Profiling completed successfully!")
final_filename = f"{profile_name}_{backend}.hatchet"
logger.info(f"Profile file: {final_filename}")
logger.info(f"View with: proton-viewer {final_filename}")
if __name__ == "__main__":
main()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
$ proton profile_softmax.py --M 4096 --N 32000 --backend torch
$ proton-viewer -m time/ms ./softmax_profile_torch.hatchet
656.702 ROOT
├─ 0.543 _ZN2at6native29vectorized_elementwise_kernelILi4ENS0_13AUnaryFunctorIN3c104HalfES4_S4_NS0_15binary_internal10MulFunctorIfEEEESt5arrayIPcLm2EEEEviT0_T1_
├─ 655.861 _ZN2at6native43_GLOBAL__N__b6de9c8c_10_SoftMax_cu_9f978f6319cunn_SoftMaxForwardILi8EN3c104HalfEfS4_NS1_22SoftMaxForwardEpilogueEEEvPT2_PKT0_i
└─ 0.298 _ZN2at6native54_GLOBAL__N__d8ceb000_21_DistributionNormal_cu_0c5b6e8543distribution_elementwise_grid_stride_kernelIfLi4EZNS0_9templates4cuda20normal_and_transformIN3c104HalfEfPNS_17CUDAGeneratorImplEZZZNS4_13normal_kernelIS9_EEvRKNS_10TensorBaseEddT_ENKUlvE_clEvENKUlvE1_clEvEUlfE_EEvRNS_18TensorIteratorBaseET1_T2_EUlP24curandStatePhilox4_32_10E0_ZNS1_27distribution_nullary_kernelIS7_f6float4S9_SO_SH_EEvSJ_SL_RKT3_T4_EUlifE_EEvlNS_15PhiloxCudaStateESK_SL_
$ proton profile_softmax.py --M 4096 --N 32000 --backend triton
$ proton-viewer -m time/ms ./softmax_profile_triton.hatchet
668.793 ROOT
├─ 0.543 _ZN2at6native29vectorized_elementwise_kernelILi4ENS0_13AUnaryFunctorIN3c104HalfES4_S4_NS0_15binary_internal10MulFunctorIfEEEESt5arrayIPcLm2EEEEviT0_T1_
├─ 0.302 _ZN2at6native54_GLOBAL__N__d8ceb000_21_DistributionNormal_cu_0c5b6e8543distribution_elementwise_grid_stride_kernelIfLi4EZNS0_9templates4cuda20normal_and_transformIN3c104HalfEfPNS_17CUDAGeneratorImplEZZZNS4_13normal_kernelIS9_EEvRKNS_10TensorBaseEddT_ENKUlvE_clEvENKUlvE1_clEvEUlfE_EEvRNS_18TensorIteratorBaseET1_T2_EUlP24curandStatePhilox4_32_10E0_ZNS1_27distribution_nullary_kernelIS7_f6float4S9_SO_SH_EEvSJ_SL_RKT3_T4_EUlifE_EEvlNS_15PhiloxCudaStateESK_SL_
└─ 667.948 softmax_forward
It reproduces that triton version is worse but I wasn’t able to get useful insight out of it – may be I am using it wrong – but ncu seemed to be a lot more useful!
Summary
Performance profiling using NCU revealed that the Triton softmax kernel shows degraded performance due to increased warp stalls, likely due to non-negative value checks before sqrt in triton version
Key findings:
- Warp latency: Triton kernel shows 14.43 vs 11.99 cycles per instruction compared to PyTorch
- Stall cause: Excessive time spent in floating-point validation routines (
CALL.REL.NOINC 0x70efb7c4c750) - Warp divergence: The validation code handles negative/NaN/infinity checks causing significant branching overhead
- Assembly difference: PyTorch implementation avoids this validation bottleneck entirely
The performance gap stems from compiler-generated safety checks rather than algorithmic differences – I guess another debugging exercise for another day! ✌️